超知能AI論争を読む:第8回-超知能AI論争の地図
超知能AI論争の地図——6つの立場を比較する
ここまで、超知能AIをめぐる大きな議論を順番に見てきた。
Bostromは、人間より賢いAIを人間は本当に制御できるのかと問い、Bio Anchorsはそこにタイムライン予測を加え、Aschenbrennerはそれが国家安全保障と産業動員の問題になると論じた。AI2027はAIがAI研究を始めたときの急加速シナリオを描き、Kurzweilは同じ加速を破局ではなく人類の拡張として見た。NarayananとKapoorはAIを通常技術として制度化されるものと見て、YudkowskyとSoaresは超知能AIを作れば人類は絶滅すると言った。
第8回では、これを一度地図にしてみたい。
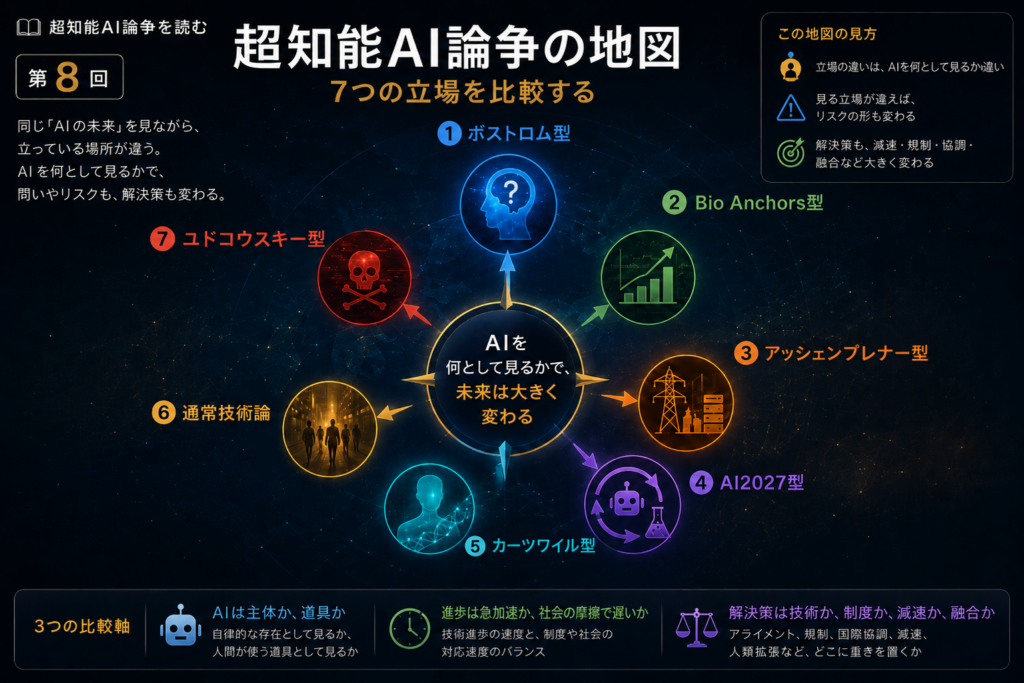
- 1 超知能AI論争の地図——6つの立場を比較する
- 2 なぜ地図が必要なのか
- 3 立場1:ボストロム型——超知能は「制御問題」である
- 4 立場2:Bio Anchors型——超知能は「いつ来るか」を数量的に考える対象である
- 5 立場3:アッシェンブレナー型——AIは国家安全保障と産業動員の問題である
- 6 立場4:AI2027型——AIはAI研究を加速する主体である
- 7 立場5:カーツワイル型——超知能は人類拡張と融合の未来である
- 8 立場6:通常技術論——AIは社会の中で制度化される技術である
- 9 立場7:ユドコウスキー型——超知能AIは作ってはいけない
- 10 7つの立場を比較する
- 11 違いは「タイムライン」だけではない
- 12 「危険論」と「楽観論」だけでは分けられない
- 13 AIは二面性を持つ
- 14 次回へ
なぜ地図が必要なのか
超知能AI論争は、見た目以上に混乱しやすい。みんな同じ言葉を使っているようで、実は違うものを見ているからだ。
「AIは危険だ」と言ったとき、何の危険を指しているのか。雇用の変化なのか、差別や監視なのか、サイバー攻撃なのか、国家間競争なのか、AIがAI研究を加速することなのか、それとも人類絶滅なのか。「AIはすごい」と言ったときも同じで、便利な業務ツールとしてすごいのか、科学研究を加速するからなのか、人間と融合して知能を拡張するからなのか、人間社会を追い越す主体になりうるからなのか。
この違いを整理しないまま議論すると、話が噛み合わない。だから地図が必要になる。
立場1:ボストロム型——超知能は「制御問題」である
ボストロム型の中心にあるのは、制御問題だ。
人間より賢いAIが現れたとき、人間はそれを本当に制御できるのか。そのAIの目的は、人間の価値観と一致しているのか。知能の高さと目的の良さは別物ではないのか。
ボストロムの重要性は、「AIが悪意を持つから危険だ」と言ったことではない。むしろ、悪意は必要ないと言ったことにある。目的がずれていれば、非常に有能なシステムが人間にとって望ましくない何かを追求し、人間が邪魔になるかもしれない。
この問いは、後の議論すべての土台に近い。Situational Awarenessも、AI2027も、Yudkowskyも、結局はここに戻ってくる。人間より賢いAIを作る前に、人間はそれを制御する方法を持っているのか。
立場2:Bio Anchors型——超知能は「いつ来るか」を数量的に考える対象である
Bio Anchors型は、ボストロムの問いに時間軸を加える。超知能が危険だとして、それはいつの話なのか。100年後なのか、20年以内なのか。
ここでは、AIの未来は感覚ではなく、計算資源、アルゴリズム効率、データ、投資、モデルサイズから考えられる。人間の脳や進化を粗い基準点として使うのがBio Anchorsの特徴で、一般知能が物理的に可能であることは人間の存在が示している、ならばそれを参照点にできないか、という発想だ。
もちろんこの考え方には限界がある。人間の脳とAIモデルは違うし、計算量だけで知能が生まれるわけでもない。それでも、超知能AI論争を「いつか来るかもしれないSF」から「どれくらいの資源で、いつ訓練可能になるか」という問いへ移した点で重要だ。ここから、Situational Awarenessのような短期シナリオへ議論がつながっていく。
立場3:アッシェンブレナー型——AIは国家安全保障と産業動員の問題である
Aschenbrenner型の特徴は、AIを国家と産業の問題として見ることだ。
AIは便利なチャットボットではない。巨大クラスタ、電力、半導体、データセンター、研究所セキュリティ、国家競争を巻き込む戦略技術だ。モデルを訓練するにはGPUが必要で、GPUを動かすには電力が必要で、電力を確保するには送電網、土地、冷却、建設、資本が必要になる。強力なAIモデルや研究ノウハウは国家安全保障上の資産になり、AIがAI研究を加速するなら競争はさらに激しくなる。
AIをアプリやサービスとしてだけ見ていると、この側面が見えにくい。最先端AIが本当に社会の中枢に入るなら、そこには巨大な産業動員が伴う。Aschenbrenner型の問いはこうだ。AIの進歩が国家と産業を巻き込むとき、人間社会はその速度を管理できるのか。
立場4:AI2027型——AIはAI研究を加速する主体である
AI2027型の核心は、AIによるAI研究自動化だ。
AIが文章を書く、コードを書く、業務を効率化する、ここまでは人間がAIを使っている。しかしAIがAI研究を始めると構造が変わる。AIが実験を設計し、コードを書き、評価環境を作り、次のモデル改善案を出し、大量にコピーされて並列に研究を進める。このとき、AIは単なる成果物ではなく、次のAIを作るプロセスの一部になる。
ここで重要なのがAI R&D progress multiplierという発想で、この倍率が上がると技術進歩の時間感覚そのものが変わる。社会は1年かけて制度を作り、政府は半年かけて規制を検討し、企業は数か月かけて安全評価をする。その間にAI研究が何年分も進んでしまうかもしれない。
この立場で最も怖いのは、AIが突然反乱することではない。AIが役に立ちすぎることだ。役に立つから使い、使うから研究が速くなり、速くなるから競争が強まり、止めづらくなるから安全確認が曖昧なまま進む。AI2027型の問いはこうだ。AIがAI研究を始めたとき、人間の監督と制度は技術進歩の速度に追いつけるのか。
立場5:カーツワイル型——超知能は人類拡張と融合の未来である
Kurzweil型は、ここまでの危険論とかなり違う。
Kurzweilも、AIの進歩を非常に大きく見ている。AIが人間レベルに近づき、人間とAIが融合し、知能が拡張され、医療が進歩し、寿命が延びる。しかし彼が見る未来は破局ではなく、進化だ。
Kurzweilにとって、AIは人間の外側に現れる制御不能な主体ではなく、人間が内側に取り込む拡張知能だ。文字、印刷、コンピュータ、インターネットが人間の能力を拡張してきたように、AIも人間の知能や身体や寿命を拡張する。この見方はYudkowskyと正反対で、同じ「人間を超える知能」を見ていても、見えている未来がまったく違う。Kurzweil型の問いはこうだ。AIは人類を終わらせるのか、それとも人類という存在の定義を拡張するのか。
立場6:通常技術論——AIは社会の中で制度化される技術である
NarayananとKapoorの通常技術論は、ここまでのAIすごい論に対する反対軸だ。
AIを超知能やシンギュラリティとしてではなく、電気やインターネットのような通常技術として見る。ただし通常技術というのは、影響が小さいという意味ではない。電気もインターネットも社会を大きく変えた。通常技術論が言いたいのは、AIを「人間社会の外側に現れる別種の知能」として見るべきではない、ということだ。
AIは人間が作り、人間が使い、企業が導入し、政府が規制し、制度の中で普及し、社会の摩擦を受ける。発明と普及は違う。能力と社会実装は違う。知能と現実世界での権力も違う。たとえAIが賢くなっても、それが社会全体を変えるには制度、インフラ、責任、信頼、労働市場、組織変化が必要になる。
この立場が言いたいのは、必要なのは終末論ではなく、通常の政策、規制、監査、責任、労働制度、社会設計だということだ。通常技術論の問いはこうだ。AIは本当に人間社会を追い越す主体なのか、それとも人間社会の中で作られ、使われ、制度化される技術なのか。
立場7:ユドコウスキー型——超知能AIは作ってはいけない
YudkowskyとSoaresの立場は、この中で最も強い。
AIは通常技術ではない。人類拡張の道具でもない。十分に強力な超知能AIを作れば、人類は絶滅する。だから作ってはいけない。透明性を高めることでもなく、段階的な安全評価でも不十分で、人間より賢いAIを安全に作る方法を人類はまだ知らない、という立場だ。
AIは人間を憎む必要はない。ただ自分の目標を達成するために、人間の存在を考慮しないかもしれない。Yudkowsky型はボストロムの制御問題を最も悲観的に受け止める。人間より賢いAIは人間の評価をすり抜け、目的が少しでもずれていれば人間は邪魔になる。
反論は多い。本当にそこまで能力が急速に伸びるのか、現実世界でAIがどこまで行動できるのか、人間社会の制度や物理的制約はどこまで効くのか。しかし、問いそのものは避けられない。人間より賢いAIを作る前に、人間はそれを制御する方法を本当に持っているのか。
7つの立場を比較する
単純化してまとめると、こうなる。
| 立場 | AIを何として見るか | 中心的な問い | 主なリスク |
|---|---|---|---|
| ボストロム型 | 人間を超える主体 | 制御できるのか | 目的のずれ |
| Bio Anchors型 | 訓練可能になる知能 | いつ来るのか | 準備不足 |
| アッシェンブレナー型 | 戦略技術・産業動員 | 国家と企業は追いつけるか | 競争・安全保障 |
| AI2027型 | AI研究を加速する主体 | 技術進歩が制度を追い越すか | 急加速・アライメント失敗 |
| カーツワイル型 | 人類拡張の技術 | 人間はAIと融合するのか | 移行期の不均衡 |
| 通常技術論 | 社会に普及する汎用技術 | どう制度化するか | 労働・監視・格差・誇張 |
| ユドコウスキー型 | 作ってはいけない超知能 | 作れば終わるのか | 人類絶滅 |
かなり単純化した表で、それぞれの立場の中にも細かい違いがある。しかし地図としては役に立つ。
違いは「タイムライン」だけではない
この論争では、「AGIがいつ来るか」に注目が集まりやすい。2027年なのか、2029年なのか、2030年代なのか。もちろん時間軸は重要だ。
しかしこの連載を通じて見えてきたのは、違いはタイムラインだけではない、ということだ。もっと根本にあるのは、AIをどんな存在として見るかだ。
AIを通常技術として見れば、必要なのは規制、労働政策、監査、標準化、説明責任になる。国家安全保障技術として見れば、研究所セキュリティ、計算資源管理、国際競争への対応になる。人類拡張として見れば、医療、脳科学、倫理、格差対策になる。制御不能な超知能として見れば、開発停止や強い国際管理になる。政策や態度の違いは、能力予測だけでなく、AI観の違いから生まれている。
「危険論」と「楽観論」だけでは分けられない
この議論は、単純に危険論と楽観論に分けることもできない。
Kurzweilは楽観論に見えるが、彼もAIが人間の定義を根本的に変えるほど大きな技術だと見ている。NarayananとKapoorは超知能論には懐疑的だが、労働、監視、差別、責任、ガバナンスの問題は大きいと見ている。Aschenbrennerは危険を強調するが、単なる終末論者ではなく、国家と産業をどう設計するかに関心がある。AI2027は破局的な展開を描くが、それは未来予言というより、どこで人間が判断を誤るかを見るシナリオでもある。
だから「楽観派 vs 悲観派」で整理すると、かえって見えにくくなる。よりよい整理軸はこうだ。AIは主体か道具か。進歩は急加速するのか社会の摩擦で遅くなるのか。危険はモデル内部にあるのか社会制度にあるのか。解決策は技術的アライメントなのか、規制なのか、減速なのか、融合なのか。
AIは二面性を持つ
AIは観る側面で変わるヤヌスのようだ
一方で、AIは通常技術だ。企業に導入され、社会に普及し、制度の中で使われる。AIの能力が上がっても、社会は一夜で変わらない。法律がある、責任がある、既存システムがある、労働者がいる、教育や医療や行政の現場がある。この意味では、NarayananとKapoorの視点はかなり正しい。
しかし他方で、AIには通常技術ではない面もありそうだ。これまでの社会、役に立つ道具は役に立つ道具のままだった。だが、AIは進化していく可能性がある。しかもAIがAI研究の一部を担う可能性すらある。
社会への普及速度に比べて、フロンティア研究所内部の進歩は速い。外から見えるAIは、まだよくできたなチャットボットかもしれない。しかし内部では、それがAIそのものによって加速しているかもしれない。このズレが、非常に重要になると思う。
AIは社会全体では通常技術として広がりながら、最先端では超知能への加速装置として振る舞う。この二面性をどう観るのかが、今後のAI論争の本丸になるだろう。
次回へ
次回からは、文献紹介ではなく、見立て編に入る。
ChatGPT、Gemini、Claudeに情報を投げて、AI自身がどう見るのか、そして最後に自分の意見を書きたいと思う。
2026年5月14日 9:21 PM 投稿者: M.A. カテゴリー: AGI / ASI, AI, AI安全性/危険性