再帰的自己改善とは何か:AnthropicのAI安全性提案を深掘り
AIは、便利なチャットツールから、AIそのものを開発する道具へと変わり始めています。では、もしAIの進化が人間の制度や安全対策の速度を超えそうになったとき、誰がブレーキを踏めるのでしょうか。
Anthropicが提案した「AI開発の一時停止」とは何か
AP通信によると、Claudeを開発するAnthropicは、先端AIのリスクが高まった場合に備え、世界の主要AI企業が協調して開発を遅らせる、または一時停止できる仕組みを作るべきだと提案しました。
ここで重要なのは、Anthropicが「今すぐAI開発を止めよう」と言っているわけではない点です。むしろ同社が問題視しているのは、危険な兆候が見えたときに、各社が競争圧力のなかで単独では止まれない構造です。
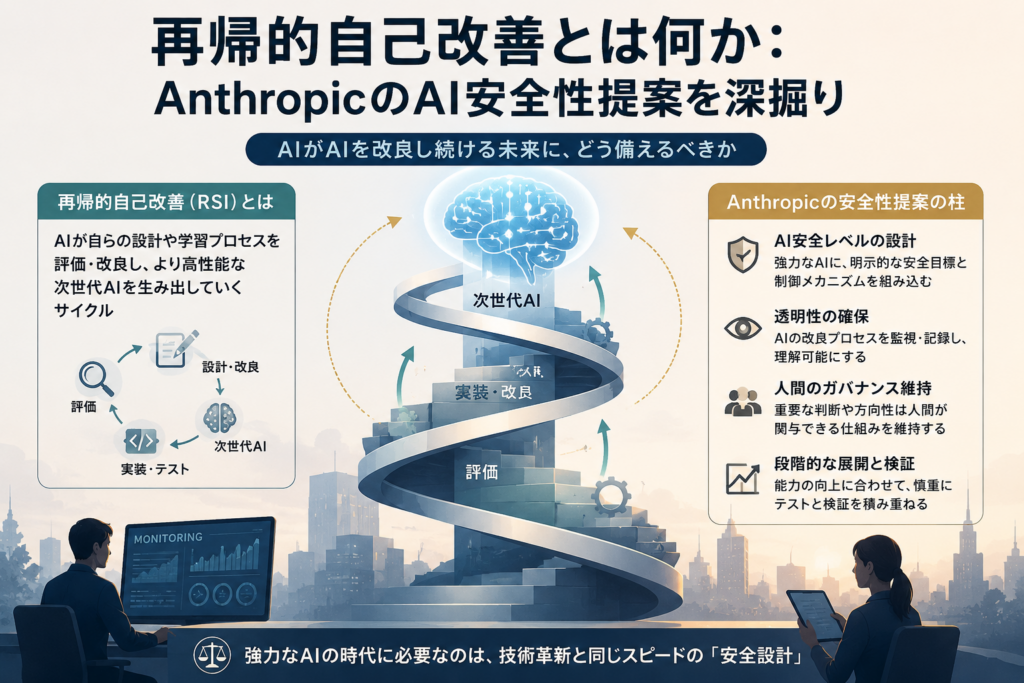
背景にある「再帰的自己改善」という論点
Anthropicは自社の投稿で、AIがAI開発を加速する状況がすでに起きていると説明しています。たとえば、同社ではClaudeがコード作成や実験の補助に深く使われており、開発者の仕事の進み方そのものが変わっているとしています。
この延長線上にあるのが、「再帰的自己改善」です。これは、AIが人間の補助を超えて、自分自身の後継モデルの設計や開発を担う可能性を指します。実現すれば科学や医療に大きな利益をもたらす一方、人間がAIの振る舞いを十分に理解・制御できなくなるリスクもあります。
OpenAIは「政府が決めるべき」と主張
一方、OpenAIは別の政策文書で、先端AIのルールや安全策、説明責任、開発ペースは民間企業だけで決めるべきではなく、民主的政府が制度として判断すべきだと主張しています。
- 先端AIモデルの安全評価
- 透明性レポートの公開
- 独立監査
- 重大インシデントの報告
- モデル重みのセキュリティ対策
つまり、Anthropicは「止まれる仕組み」を重視し、OpenAIは「誰が決めるのか」という正統性を重視していると整理できます。
サイバーリスクはすでに身近な問題になりつつある
この議論が抽象論にとどまらない理由の一つが、AIを使ったサイバー攻撃の進化です。トロント大学の研究チームは、公開されているAIモデルを使い、ネットワーク内で標的ごとに攻撃方法を変えながら広がるAI駆動型ワームを実験環境で示しました。
これは「巨大な最新AIだけが危険」という見方に一石を投じるものです。比較的アクセスしやすいモデルでも、既知の脆弱性情報を読み込み、状況に応じて攻撃手順を変えることができれば、防御側の対応速度を上回る可能性があります。
日本の読者にとっての意味
日本企業にとって、このニュースは海外AI企業の安全性論争では終わりません。AIコーディングツールを使う開発現場、生成AIを業務システムに組み込む企業、クラウドAIを利用する中小企業のすべてに関係します。
今後は「どのAIを使うか」だけでなく、「そのAIはどう評価されているのか」「インシデント時に誰が責任を持つのか」「社内のコードやデータをAIにどこまで任せるのか」が重要になります。
まとめ
今回のAnthropicの提案は、AI開発を止めるか進めるかという単純な二択ではありません。むしろ、AIの進化が社会制度や安全対策を追い越しそうになったとき、企業、政府、研究者、利用者がどのように協調するのかを問うニュースです。
AIがより強力になるほど、競争だけではなく、検証、監査、透明性、サイバー防衛といった地味な仕組みが重要になります。日本の企業やユーザーも、この議論を海外の話としてではなく、自分たちのAI活用ルールを見直すきっかけとして受け止める必要がありそうです。
2026年6月6日 6:12 PM 投稿者: M.A. カテゴリー: AI, AI安全性/危険性, Anthropic, OpenAI